SaltMiner regularly indexes json documents into Elasticsearch. EG:
var issues = new List<Issue>();
var issueCount = 11;
for (var index = 0; index < issueCount; index++)
{
var issue = Mock.Issue(assetType, sourceType);
issue.Id = "";
issue.Saltminer.Source.IssueStatus = "SearchTest";
issues.Add(issue);
}
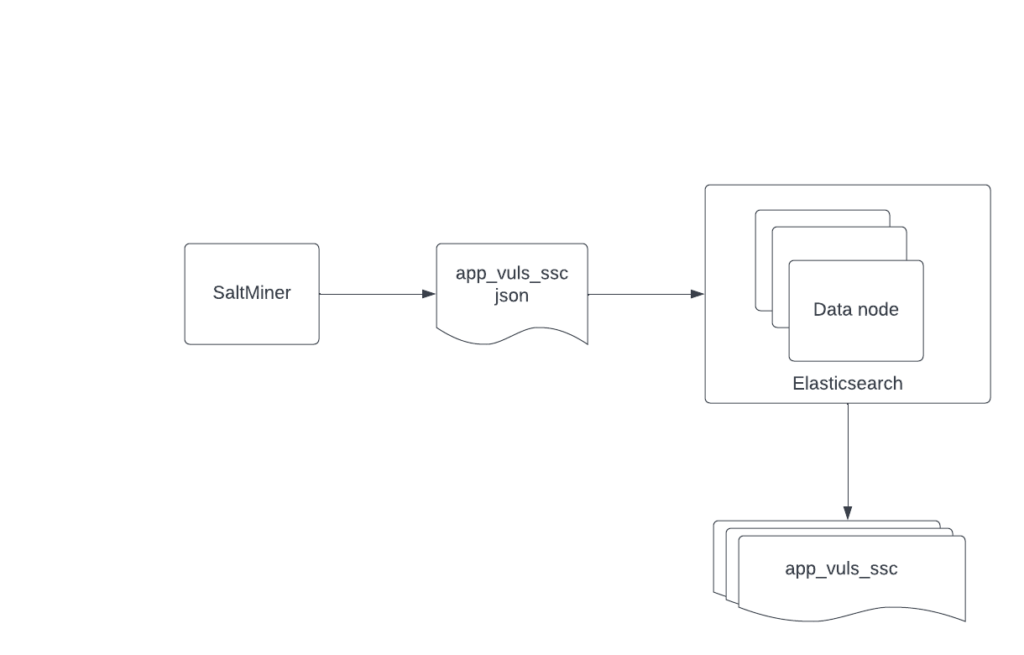
Client.AddUpdateBulk(issues); The Client.AddUpdateBulk(issues) command on line 12 results in a _bulk {…} command being sent to Elasticsearch, where the contents of the command are the JSON serialized results of each “issue” are in the body. The illustration below shows a normal data flow for a document sent by SaltMiner. It’s posted to the Elasticsearch cluster, which then indexes it.
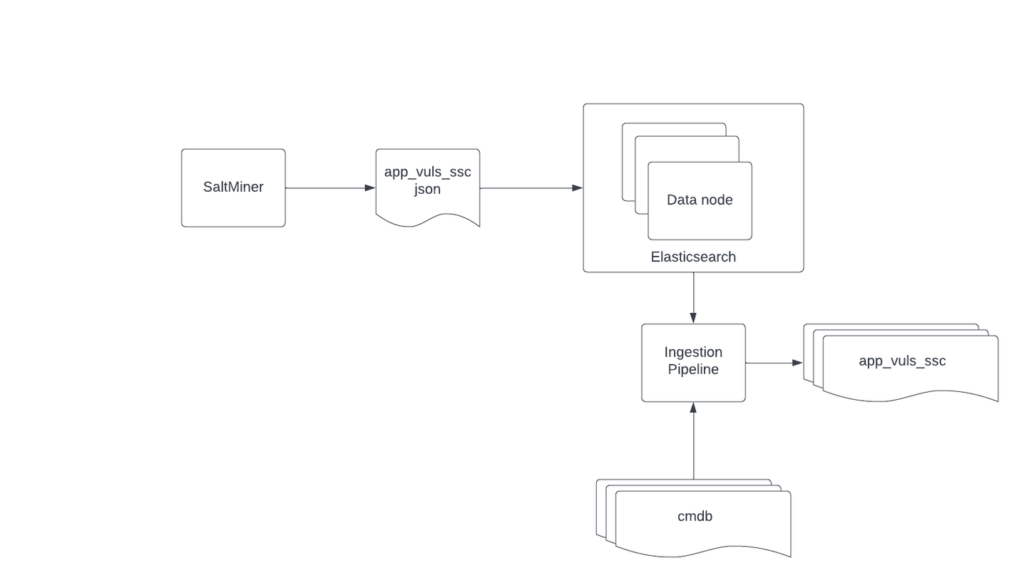
Whenever you post a document to an index, you can have that document first be “processed” by an Ingestion Pipeline (Ingest pipelines | Elasticsearch Guide [8.1] | Elastic) as illustrated below:

Ingestion Pipelines offer an easy way to get between what SaltMiner is posting and what is being indexed. They allow you to manipulate the incoming document as needed before it’s indexed. The most common ways Ingestion Pipelines have been used to date are the following:
- Enrichment
- As a document is indexed, you can bring in data from a different index by matching on an id field.
- Uppercasing
- At some companies, Ingestion Pipelines are used to upper case attributes.
When you setup an Ingestion Pipeline, you can specify any number of Processors (Ingest processor reference | Elasticsearch Guide [8.1] | Elastic) to manipulate your document.
Enrichment
One of Ingestion Pipelines’ most useful features is Enrichment. In the example below, Enrichment is used to add CMDB information to an app_vuls_ssc document as it’s indexed. This means an id in the app_vuls_ssc document matches the id of a document in the CMDB index. That causes the CMDB document’s data to be added to the incoming app_vuls_ssc document.
Here are the steps required to setup an Ingestion Pipeline with an Enrichment Policy:
- Identify your lookup index. Your lookup index is an index holding data that should be added to incoming documents. Common examples are CMDB data or HR data. Each document in this index should be uniquely identified by a single field. If each document is uniquely identified by more than one field, the two fields need to be concatenated together into a single keyword field that can be matched on. At some companies, the index that contains CMDB data is named “apps”. There is a team responsible for posting to this index daily.
- Create an Enrichment Execution Policy (Create enrich policy API | Elasticsearch Guide [8.1] | Elastic). An Enrichment Execution Policy tells Elasticsearch to create a lookup index, using the “match_field” as the lookup value. Below is the Enrichment Execution Policy used for the applitecture index at ACME.
{
"policies" : [
{
"config" : {
"match" : {
"name" : "applitecture-policy",
"indices" : [
"applitecture"
],
"match_field" : "asset_tag",
"enrich_fields" : [
"source",
"source_id",
"managed_by",
"mf_alias",
"mf_name",
"owned_by",
"risk_rating",
"studio_name",
"support_group",
"supported_by"
]
}
}
}
]
}
3. Execute Enrichment Policy. After an Enrichment Execution Policy is created, it must be executed (Execute enrich policy API | Elasticsearch Guide [8.1] | Elastic). Executing an Enrichment Execution Policy tells Elasticsearch to create a special, internal, index based off of the documents in the index specified in the policy. Whenever the documents in the underlying index change, you must re-execute the policy. SaltMiner has extension points for custom code. Executing enrichment policies is a common step in these areas.
4. Add Policy to Ingestion Pipeline. After the Enrichment Execution Policy has been executed, you can add it to an Ingestion Pipeline. You can create Ingestion Pipelines via Dev Tools, but Kibana makes it very simple (Ingest pipelines | Elasticsearch Guide [master] | Elastic). Below is the Ingestion Pipeline that targets the Enrichment Execution Policy from step 3.
[
{
"enrich": {
"description": "Adds Applitecture data based on asset_tag",
"policy_name": "applitecture-policy",
"field": "asset_tag",
"target_field": "applitecture",
"max_matches": "1"
}
}
]The “enrich” JSON section is known as an Enrichment Processor. Ingestion Pipelines are made up of one or more processors. The “enrich” processor allows an Ingestion Pipeline to target an Enrichment Execution Policy. Line 5 tells the enrichment process which policy to use. Line 6 tells the enrich processor that when a document is about to be indexed, the incoming document will have an “asset_tag” field. That “asset_tag” field on the incoming document should be matched against the “match_field” property specified in step 3 on Line 10. This is how the CMDB information is matched. Line 7 tells the enrich processor to place all values from the CMDB document that is matched under the “applitecture” field in the incoming document. Below is an example of an enriched document:
{
"_index": "pen_vuls_rl",
"_source": {
"score_base": "0",
"timestamp": "2022-03-31T20:08:19.515069",
"severity": "Low",
"scan_status": "Completed",
"confidence": "",
"applitecture": {
"asset_tag": "[redacted]",
"mf_name": "[redacted]",
"managed_by": "[redacted]",
"source": "[redacted]",
"source_id": "[redacted]",
"mf_alias": "[redacted]"
},
"issue_status": "Open",
"message": "",
"category": "Application"
}
}If you notice Line 9 has the “applitecture” field. This field and the contents under it were added as the pen_vuls_rl document was indexed.
5. Assign the Ingestion Pipeline to an Index. The final step is configuring an index to push its documents through a pipeline as they’re indexed. Each index has an “index.default_pipeline” field that can be specified in its settings. This is the default_pipeline setting of the pen_vuls_rl index in the Deloitte environment. Because of this setting, every document added to this index will go through the “applitecture-lookup” ingestion pipeline.
{
"index.default_pipeline": "appinventory-lookup",
}Naming Conventions
I suggest naming Enrichment Execution Policies after the index they target. EG:
The policy for the “ACME-cmdb” index would be “ACME-cmdb-execution-policy”. This makes it clear.
The Ingestion Pipelines should be named according to what they do. EG) there could be a single Ingestion Pipeline you want all documents for all indices to go through that upper cases a single field that’s common to all of them. In this example it would be “Upper-Case-Id-Field-Pipeline”. Ingestion Pipelines can be composed. Building them up can be really useful when trying to make sure a specific transformation is applied to all documents.